DeepSeek V3-0324 模型更新分析报告,被我和AI协作的9张图总结了
发布日期:2025-04-18 浏览次数:117
来源:纵所周知101
基本信息

发布时间:2025年3月24日
版本性质:V3的小版本更新,非V4或R2的发布
模型规模:6850亿参数(MoE架构,激活参数约370亿)
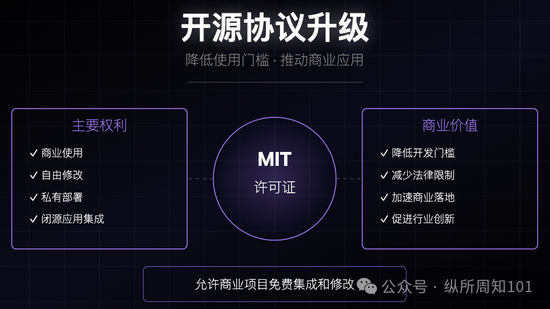
开源协议:升级为MIT许可证,允许商业项目自由集成和修改
部署渠道:官方网站、App和小程序均已开放使用
核心能力升级
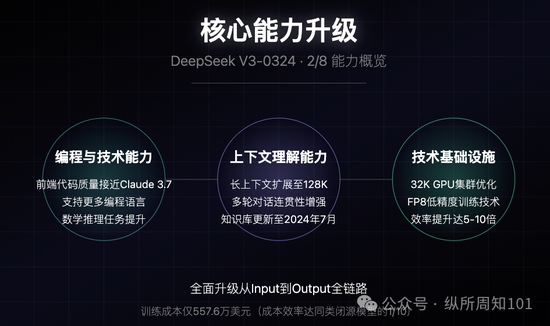
1. 编程与技术能力
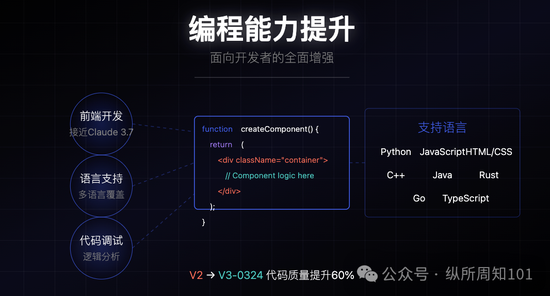
前端代码生成质量接近Claude 3.7水平(行业标杆)
支持更多编程语言(Python、C++、Java、Rust等)
数学与逻辑推理任务表现提升,部分测试接近专用推理模型
代码调试和逻辑分析能力增强,提供更准确的修改建议
2. 上下文理解与长文本处理

长上下文记忆扩展至128K,支持论文、代码库等分析
多轮对话中展现更强的连贯性和意图追踪能力
知识库更新至2024年7月,涵盖最新进展
语言表达更自然,贴近人类交流习惯
3. 技术基础设施与性能
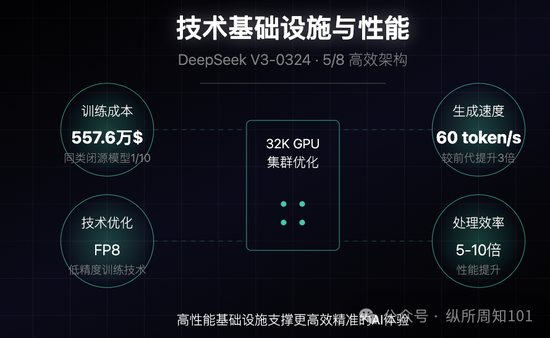
基于32K GPU集群优化的训练流程
沿用FP8低精度训练技术,降低资源消耗
生成速度达60 tokens/秒,较前代提升3倍
总训练成本仅557.6万美元(成本效率达同类闭源模型的1/10)
部分场景处理效率提升达10倍(实际使用可能为5-6倍)
从输入理解与输出反馈角度的分析
其实模型的能力无外乎,用户输入信息(Input)的理解,
和理解后输出(output)信息的反馈
输入理解(Input)能力

理解广度增强:支持更多专业领域输入,尤其在代码和技术文档方面
理解深度提升:长文本理解能力强化,能处理大规模输入并提取关键信息
意图识别优化:更准确识别用户在复杂多轮对话中的真实需求
上下文关联:能够关联前几轮对话内容,形成连贯理解
容量提升:128K上下文窗口使模型能处理更庞大的输入信息量
输出反馈(Output)能力
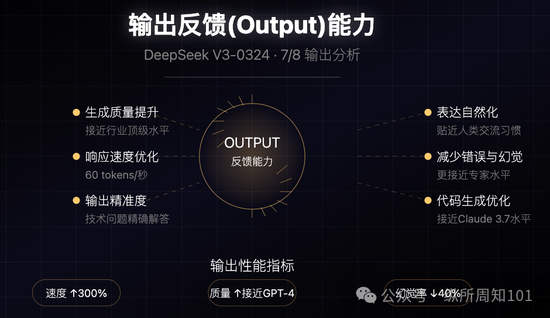
生成质量提升:尤其在代码生成方面,输出接近行业顶级水平
响应速度优化:生成速度大幅提升,用户体验更流畅
输出精准度:在技术问题解答和代码调试建议上更为精确
表达自然化:语言输出更贴近人类交流习惯
减少错误与幻觉:生成的专业内容更接近专家水平
Input-Output协同优化
连贯性增强:输入理解与输出生成的逻辑链接更紧密
复杂任务处理:能将复杂问题分解为有序步骤,并提供系统性解决方案
适应性反馈:根据用户后续输入调整理解方向和输出策略
任务完成效率:多步骤指令执行连贯性提高,整体任务完成质量提升
交流成本降低:对用户意图的精准追踪减少了交流成本和迭代次数
行业影响与未来展望
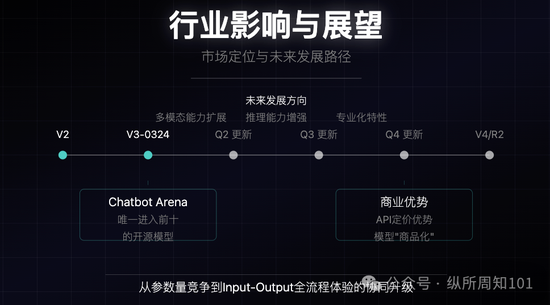
在Chatbot Arena等评测平台中是唯一进入前十的开源模型,接近GPT-4o和Claude 3.5-Sonnet性能
被视为R2或V4大版本发布前的铺垫,业界预期每季度会有新版本发布
API定价优势吸引开发者,加速模型“商品化”趋势
多模态能力仍待扩展,未集成图像/语音生成,但现有能力已达“非推理模型顶尖水平”
行业对“预训练是否终结”存在分歧(xAI认为收效有限,OpenAI则认为仍有空间)
MIT协议的采用降低了开发者使用门槛,推动企业级应用发展
总结
此次V3-0324更新虽定位为小版本,但通过对理解与反馈全链路的优化,展现了DeepSeek在技术迭代上的完整策略。这种升级模式表明,大语言模型的发展已从单纯参数量的竞争转向Input-Output全流程体验的协同升级。开发者可重点关注其MIT协议带来的商业应用潜力,企业用户则适合将其用于代码生成、长文档分析和复杂推理任务。
PS:加入我的 VIP AI 社群,AI 觉醒星球,公众号点击“登录觉醒星球”获取。我将持续分享 AI 写作,AI 智能体,AI+Ip 的实操。额外福利:60 篇精品带案例原创文,每月更新觉醒星球提示词库,AI 变现的针对星球用户免费的火箭计划。
 海量资讯、精准解读,尽在新浪财经APP
海量资讯、精准解读,尽在新浪财经APP
责任编辑:石秀珍 SF183
- 上一篇:没有了
- 下一篇:没有了



